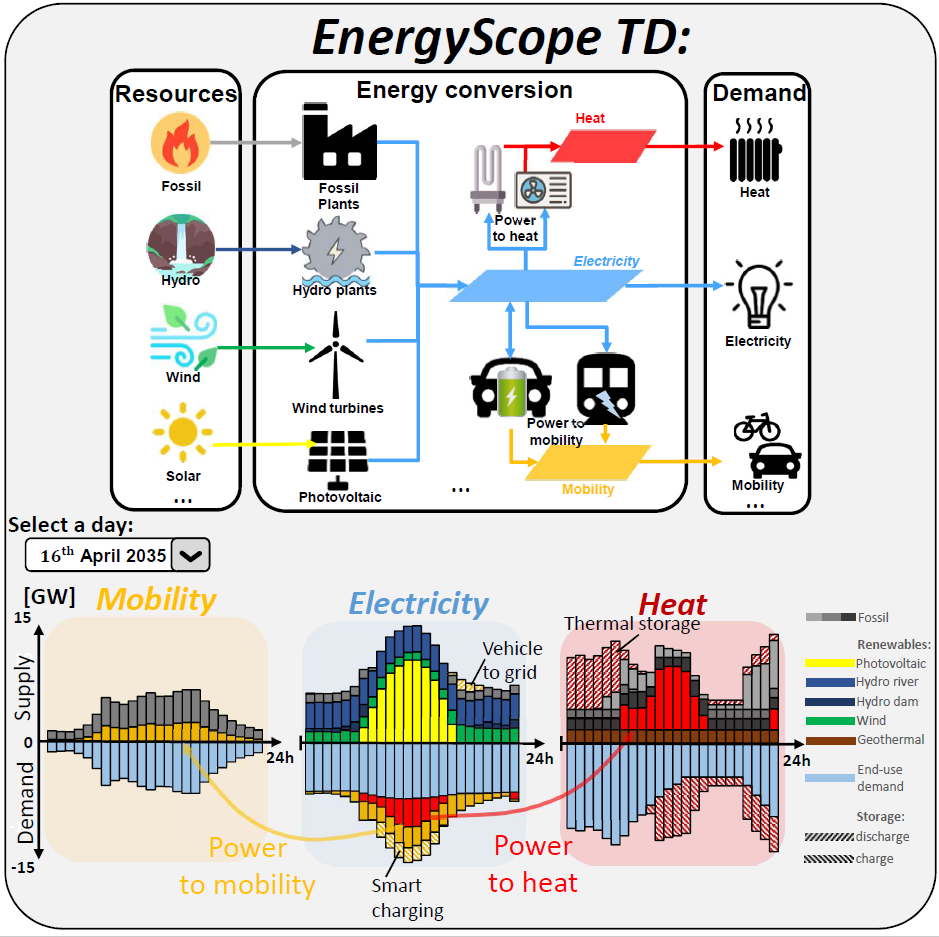
Getting started¶
The model is a mathematical formulation of a linear programming. Ith can be solved with different solvers: CPLEX, Gurobi, GLPSOL, etc. The model was originally developed in AMPL. Running the model in AMPL requires the licences of AMPL and of at least one LP solver.
The energy model requires pre and post processing. In version 2.2 and before, the pre-processing was done with excel files. In the following version, we improved it to Python, making it more universal and powerful.
Caution
For users that just want to try the model in 10 minutes without installing the software, we advise to check a former version: repository and documentation. This version will allow you to use GLPK and GLPSOL which are open source. The drawback being the computational time that soars at 30 minutes.
In the following, we will present how to install the solver and configure python. We are using AMPL, however, other languages could be use (under investigation).
Install AMPL:¶
AMPL (A Mathematical Programming Language) is an algebraic modeling language to describe and solve high-complexity problems for large-scale mathematical computing (i.e., large-scale optimization and scheduling-type problems). AMPL supports dozens of solvers, both open source and commercial software , including CBC, CPLEX, FortMP, MINOS, IPOPT, SNOPT, KNITRO, and LGO. (source: Wikipedia 08/03/2022)
In our case, we use CPLEX solver and linear programming.
Download AMPL files depending on your OS:¶
These files contain the AMPL routines, License and solvers… Everything needed to run ampl on your machine.
- For UCLouvain students:
The model is used in courses and for master thesis at UCLouvain. An AMPL license has been made available for this purpose. Find it on the link.
You can put it in any directory of your computer (ex: C:/Program Files/ampl_mswin64). We advise to put in a path that won’t change to avoid breaking the link.
- For other users:
Different offers exist on the AMPL website. It is possible to get a free license for Academia.
Add AMPL to PATH variable:¶
This step is required to make AMPL executable from command lines.
To avoid having AMPL files at the same location as the ESTD files, add the AMPL files (and executable) it in the environment variable.
Procedure depending on OS:
after adding the AMPL files in the a folder (e.g. $HOME/Documents/Software/AMPL), run in a terminal:
(”$ “ here below stands for the beginning of a command line to enter in the terminal)
$ echo $SHELLto see which shell is used on your computer. The result should end with zsh or bash.
Depending on it:
If your shell is *zsh*, do the following.
Run in your terminal:
$ ls -la ~/ | grep zsh # To see if you have a 'zsh' file in your HOME folderIf you see a file named .zshrc, or .zsh, use that file in the following commands.
If none of those file exist, create .zshrc by running the command touch ~/.zshrc.
Open this file with:
$ open ~/.zshrc # Or '~/.zsh'then add this line at the end of the file:
export PATH=”$YOUR_PATH:$PATH”, with YOUR_PATH the path to the directory containing ampl.exe and cplex.exe
save the file. Finally, you will need to close your terminals and open a new one to run ESTD.
If you have an error saying “zsh: command not found”, follow these steps (under this toggle).
In your terminal, enter the command:
$ export PATH="/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin"Then, when you are editing your .zshrc or .zsh, add this (same) line at the beginning of the file:
export PATH=”/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin”
If your shell is *bash*, do the following.
Run in your terminal:
$ open ~/.bash_profile
then add this line at the end of the file:
export PATH=”$HOME/Documents/Software/AMPL:$PATH”,
save the file. Finally, you will need to close your terminals and open a new one to run ESTD.
edit your .bashrc with:
$ nano ~/.bashrc # Or use another editor, instead of 'nano'
then add this at the end of the file: export PATH=$PATH:/HOME/Documents/Software/AMPL,
save the file (using Ctrl+X, then Y, then Enter if you use ‘nano’). Finally, you will need to close your terminals and open a new one to run ESTD.
To test that AMPL is well installed and well saved in the environment variable, write ampl in your shell:
C:\>ampl
ampl:
(Example with Windows. Similar for macOS and Linux.)
You can quit ampl by writing q and enter.
If your shell prints:
'ampl' is not recognized as an internal or external command,
operable program or batch file.
It means that your installation of ampl didn’t work. Look at the FAQ below.
Install and run EnergyScope TD:¶
Download and install EnergyScope TD:¶
Download the actual version with python interface.
Install the energyscope python package into your python environement: .. code-block:: bash
$ pip install -e PATH
where PATH is the path where the folder ”energyscope” (downloaded from github, not its subfolder) is located. Then you must restart the kern of your pythin IDE or close it and restart it.
- Documentation of the model formulation and data:
Online: what you are currently reading: https://energyscope.readthedocs.io/en/latest/
Limpens G. PhD thesis (2021). Generating energy transition pathways : application to Belgium.
Structure of EnergyScope repository (as on github):
./Data:
Contains the data for each representative year in the following files:
Demand.csv: yearly demand for the different END_USES_INPUT and and END_USES_CATEGORIES (GWh/y)
END_USES_CATEGORIES.csv: link between END_USES_CATEGORIES and END_USES_TYPE_OF_CATEGORY
Layers_in_out.csv: table giving the conversion efficiency of the different technologies
misc.json: miscellaneous data that doesn’t fit into tables
Resources.csv: energy resources characteristics (e.g. operational cost)
Storage_characteristics.csv: storage technologies specific characteristics (e.g. charge and discharge time)
Storage_eff_in.csv: efficiency of storage technologies charge
Storage_eff_out.csv: efficiency of storage technologies discharge
Technologies.csv: technologies characteristics (e.g. investment and maintenance cost)
Time_series.csv: hourly time series over the entire year of the time dependent demands (e.g. electricity and heat demand) and technologies (e.g. renewables)
Caution
Those files are the reference data files, they shouldn’t be modified, except for updates in the model. The modification of data for specific case study happens in the python script between the importation of data and the printing of .dat files.
For more details, refer to the data Section Input Data.
./Docs:
File to generate the online documentation (this page ). This is an collaborative documentation, users are invited to submit any mistake or reformulation on the github.
./energyscope:
This folder contains the python packages to pre-process, process and post-process the energy model.
./preprocessing:
The pre-processing can be split in two parts: (i) typidal days selection (td_selection) and (ii) energyscope preparation (es_pre). The last folder contains python routines used to write data files.
./td_selection:
The selection of typical days happens in three steps: (i) generating a data file based on the 8760h time series from the data folder. (ii) Optimising the typical days selection based on a revised version MILP version of the k-medoids clustering (see 22). (iii) Formatting the result
td_selection.py: defines the functions for all the td selection process.
td_main.mod: optimisation model to select typical days (based on 22)
header.txt: contains the headers of the written files
printing_outputs.run: contains instructions to print the outputs in the solver environment.
./es_pre:
The energy model needs to be built based on the data in ./Data and the results of the typical days selection. This is done in two steps:
es_read_data.py: defines the functions to read the typical days from previous folder
es_write_energy_model_data.py: defines the functions to write the data files of the energy model
To write the data files, several headers are used and contained in the following folder. This method allows to remove the text from the python code to lighten them.
./headers: contains the headers used for writing files.
./utils: contains generic python code to generate files.
./energy_model:
The processing of the model contains the linear programming model EnergyScope TD. It is composed of two type of files: (i) model (.mod) and (ii) executables (.run).
es_model.mod: mathematical formulation of EnergyScope presented in Section Energy system model.
es_run.py: defines the python code to generate the run file used by the optimiser.
./run: contains part of ‘.run’ file to print the outputs.
./postprocessing:
The post-processing allows to generate automatically several graphs and a sankey diagram. To do so, several python codes are proposed:
postprocessing.py: read and reformat some outputs
cost.py: compute the total annualised cost of the system
plots.py: generate some plots
./draw_sankey: contains files to generate an interactive sankey (html code).
We invite users to develop their own postprocessing tools in this folder.
./Scripts: - config_ref.yaml
YAML file containing the configuration information for the case study to run. It will be loaded at the beginning of a run.
A good practice is to keep the reference config file and to modify and use a copy for specific case studies.
run_energyscope.py
Main script to adapt and run for users. It allows to:
Load the configuration file
Import the input data of the modelled year
Update data into python according to the case study
Print the data into the .dat files with he ampl syntax
Run the optimisation problem
Read and postprocess the outputs
Other files:
gitignore
defines what git should ignore
environement.yml
files that defines the minimum environment to run EnergyScope
LICENSE
NOTICE
README.md
setup.py
VERSION
Results (files) generated by the framework: Once the framework has been applied, several folders and files are created to save the data used and results. In a first step (pre-processing), the typical days will be selected. Results are in the folder ./run in the preprocessing folder. In a second step (processing), the energy model will be run. Results are in folder ./case_studies presented hereafter.
preprocessing results ():
The following files are generated in ./energyscope/preprocessing/td_selection
data.dat: contains the formatted time series used for optimisation problem
log.txt: gives the detail of the execution of the optimisation
td_main.run: contains the code to execute the solver and the paths to the different used files.
energy model results (see ./case_studies):
Directory created at first run (not on github) that contains local case studies structured as follows:
the .dat files (x2) with the data for the energy system optimisation model EnergyScope
the .mod file with the linear optimization model used
the .run file with the running instructions for ampl (options, solver, prints,…)
- the output folder which contains all the outputs to analyse the results of the case study
- Structure of the output folder:
hourly_data
Folder containing the hourly data (to print it, set ‘print_hourly_data’ to True into config file) :
over the entire year for storage (energy_stored.txt) in GWh for state of charge and GW for input and output power, always in the unit of the energy layer to which the storage is associated.
over each hour of each typical day for each layer (layer_XXX.txt) in GW.
sankey
Folder containing the input2sankey.csv used to print the sankey. This graph summarise the yearly energy fluxes into the system.
Caution
The results of the sankey always have to be double checked with the year balance. There might be errors. Indeed, the generation of sankey is not automatised and if a technology or resource change, the link must be specified.
assets
Installed assets (units in the file). For each technology, the following information are printed:
c_inv (M€/GW or M€/GWh (for storage technologies)): investment cost to build this assets (not annualized)
c_maint (M€/GW/y or M€/GWh/y (for storage technologies)): maintenance cost
lifetime (y): lifetime
f_min (GW or GWh (for storage technologies)): lower bound on f
f (GW or GWh (for storage technologies)): installed capacity
f_max (GW or GWh (for storage technologies)): upper bound on f
fmin_perc ([0-1]): lower bound on f_perc
f_perc ([0-1]): relative share of a technology in a layer
fmax_perc ([0-1]): upper bound on f_perc
c_p ([0-1]): yearly capacity factor
c_p_max ([0-1]): upper bound on c_p (attention for renewables, c_p is also constrained by the time series)
tau: investment cost annualization factor
gwp_constr (ktCO2-eq./GW or GWh (for storage technolgies)): technology construction specific GHG emissions
cost_breakdown
Cost breakdown expressed in M€/y
gwp_breakdown
GWP (Global Warming Potential) breakdown expressed in kt_CO2eq/y
losses
Losses on networks in GWh/y
resources_breakdown
Used resources and potential available in GWh/y
year_balance
This directory is ignored by git
Exercices:¶
Exercice 1 - analyse the system¶
Caution
TO BE DONE